Archive Service
The Archive Service allows you to make an archive of transactions and attachments from the Corda vault which can no longer be part of an ongoing or new transaction flow. This can reduce pressure on your node’s database, and declutter your vault.
You can use Archive service commands to mark archivable items in your vault, archive them, and restore transactions from the archive when necessary.
The Archive Service consists of the following:
- Archive Service CorDapp - contains the necessary flows to mark and archive transactions.
- Archive Service Client Library - provides programmatic access to the archive service, and exposes relevant APIs.
- Archive Service Command Line Interface - allows you to perform archiving tasks from the command line.
It also makes use of the Application Entity Manager, which allows CorDapps to access off-ledger databases using JPA APIs.
The Archive Service archives Ledger Recovery distribution records associated with the archived transactions. (The tables node_sender_distribution_records and node_receiver_distribution_records are included in the archiving process.)
The Archiving Service relies on the Ledger Graph functionality. For the Archiving Service to work correctly, the Ledger Graph must load your entire graph in memory to function.
Unless you follow the guide for making Archive-friendly CorDapps, this can cause:
- Increased time to run Archiving tasks.
- Increased JVM heap memory usage while Archiving tasks are being performed.
There is also a risk of Ledger Graph initialisation failure if transactions are in progress while the graph is being loaded (initialised) – if this happens it is deemed invalid and you must restart the node to re-initialise the ledger.
In order to improve speed and memory usage when using the Archiving Service, JVM heap memory of the node can be increased to handle larger ledgers. In addition, the transactionReaderPoolSize config parameter can be adjusted upwards to use more CPU threads to increase speed, and increase the number of CPUs or cores a node has access to.
What can be archived

The Archive Service has commands you can use to identify which transactions can be archived in your vault. A fully consumed transaction or attachment will be marked as archivable when:
- There are no unconsumed transactions in the same LedgerGraph component. A LedgerGraph component is a connected group of transactions, represented as a Direct Acrylic Graph (DAG) in the LedgerGraph service.
- The transaction is not also referenced by another LedgerGraph component that contains unconsumed transactions.
- The attachment itself is not a contract attachment.
Archivable and non-archivable LedgerGraph components:
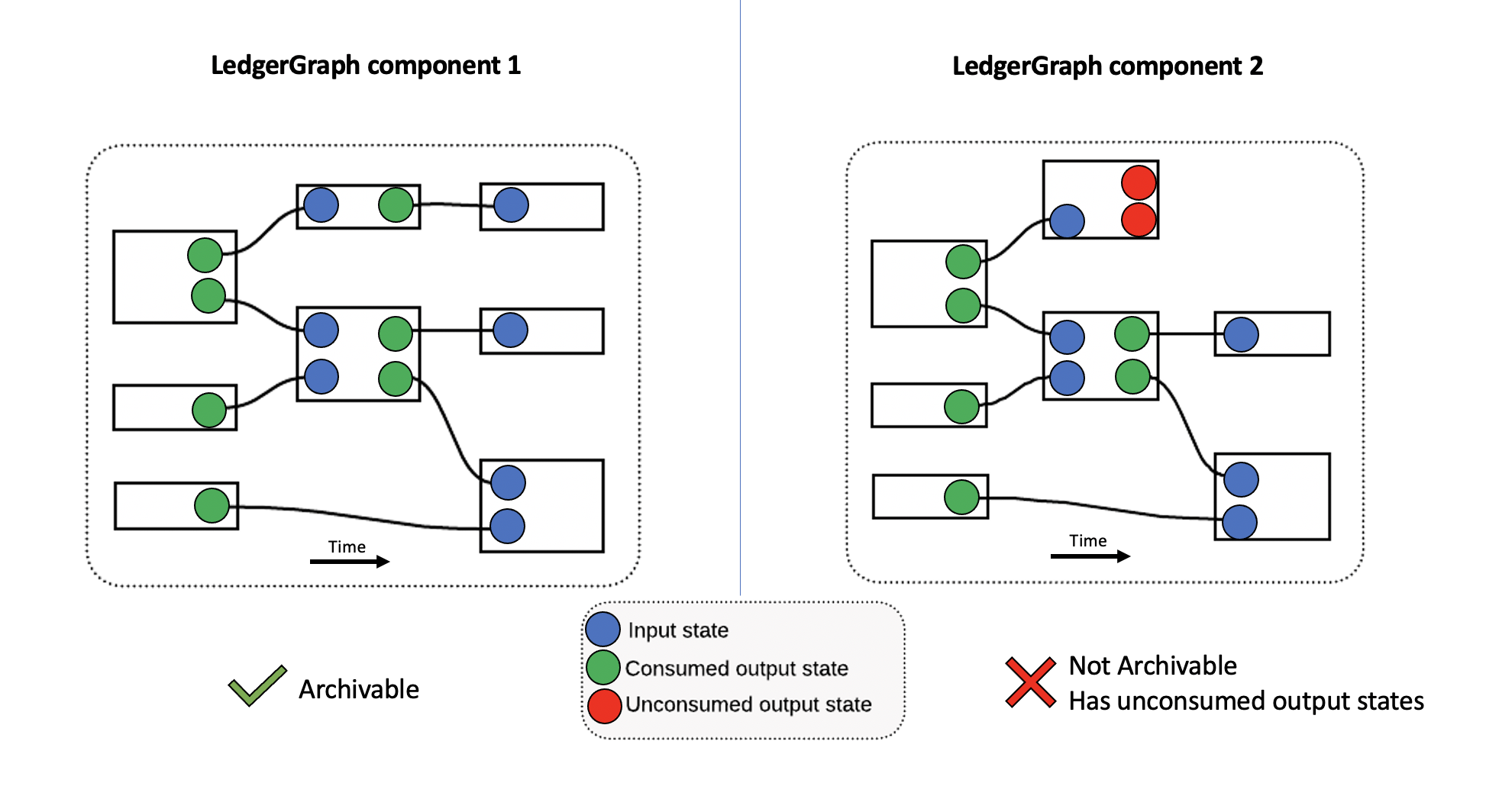
When you can archive
Once the Archive Service has marked a transaction or attachment as archivable, you can safely archive it anytime without risk to any other member of your network. You do not need to inform other members of the network, and your archiving action will not affect their ledger.
Archiving and Collaborative Recovery
The Collaborative Recovery CorDapp LedgerSync V1.2.1 has been introduced for compatibility with the Archive Service. If you or anyone on your network uses Collaborative Recovery to recover data after a disaster scenario, archived transactions in any nodes on the network are marked as such. This means that they do not appear to be ’lost’ or ‘missing’ data and will not be recovered automatically in the recovery process.
Archiving and onDemand LedgerGraph
If you are using the Archive Service with LedgerGraph V1.2.1, you can save heap memory usage by configuring the option onDemand to true in your LedgerGraph configuration settings. This means LedgerGraph is only triggered when required by the Archive Service. For example, when you make a create-snapshot request.
Making archive-friendly CorDapps
The more transactions within a Ledger Graph component, the longer it may take for a related transaction to become archivable. If you wish to create CorDapps that produce regularly archivable transactions, there are some steps you can take in your design process to help this.
Some characteristics of a good ‘archive-friendly’ CorDapp are:
- Short transaction chains that will get consumed in their entirety.
- Consumes and redeems ‘irrelevant states’ – for example if you store evolvable data it should be consumed even if it is no longer directly queried or used in a transaction.
- Avoids consuming outputs of one transaction via multiple transactions. This could mean ensuring fungible assets are distributed as narrowly as possible – rather than from multiple cash supplies.
Archive Service CorDapp
The Archive Service CorDapp enables you to use the Archiving Service to identify and perform archiving tasks. Your configuration of the Archive Service CorDapp depends on your node database.
As part of the configuration process, you can choose to create a backup schema. This is a temporary snapshot image of archivable transactions that can be used to restore the vault if the archiving process fails.
Requirements and compatibility
The Archive Service requires:
- Node minimum platform version 6.
- Corda Enterprise minimum version 4.4.
- LedgerGraph V1.2.
- Collaborative Recovery V 1.2 (if you use Collaborative Recovery).
Installation
The Archive Service CorDapp JAR file should be copied to the node’s cordapps directory. The Ledger Service CorDapp JAR file
must also be copied to the same directory.
corda@CrimsonSolo:/opt/corda/node$ ls -l cordapps/
drwxr-xr-x 2 corda corda 4096 Aug 26 06:43 config
-rw-r--r-- 1 corda corda 504538 Aug 26 06:35 archive-service-1.0.1.jar
-rw-r--r-- 1 corda corda 161260 Jul 30 05:04 ledger-graph-1.2.1.jar
Configuration
The Archive Service CorDapp is configured using a HOCON configuration file located in the config sub-directory
of node’s cordapps directory. The configuration file must have the same name and version as the CorDapp but
with the jar suffix changed to conf.
corda@CrimsonSolo:/opt/corda/node$ ls -l cordapps/config
total 12
-rw-r--r-- 1 corda corda 469 Aug 26 06:43 archive-service-1.0.1.conf
The Archive Service configuration file provides the database connection details used by the service to record a temporary snapshot of the vault data.
The following are keys for configuring the Archive Service:
generator- SQL generator, defaults to vault’s database type.driver- JDBC driver, defaults to vault’s database driver.source.schema- Vault schema name, defaults to vault database schema.target.schema- Backup schema name, optional, indicates that a backup schema should be created.target.url- Backup schema archive URL, required if a backup schema is used.target.user- Backup schema archive database user, required if a backup schema is used.target.password- Backup schema archive database password, required if a backup schema is used.
Passwords can be obfuscated using Corda’s Config Obfuscator tool.
The following is a sample configuration file:
generator: PostgresGenerator
driver: "org.postgresql.Driver"
target: {
url: "jdbc:postgresql:postgres"
user: "archive"
password: "<{HNtZpbrOGM6GhYA6foh5PCCBanUtaebCjauKL8ur9EE=:PolqmEJ7JOM+Sqj3ZNAE+Ew9bqG1wVE=}>"
schema: "archive"
}
Using the backup schema
You can configure the archiving process to create a temporary snapshot image of the archivable transactions and attachments from your Corda vault on a backup schema within the same database. This snapshot can then be used to restore the vault should the database fail during the archiving operation.
For the backup schema to work, the Corda vault schema and the archive schema must reside on the same database but be managed by different schema owners.
The Archive Service uses a separate JPA entity manager factory to manage the archive schema and copy data from the Corda schema to the archive schema.
To create a copy of the vault on the backup schema the backup schema owner must have
SELECT rights to the vault schema.
To restore the vault from a copy on the backup schema the backup schema owner must
either have INSERT rights to the vault schema or the restore-snapshot command must be executed with the
--record option.
The --record option allows the user to capture the SQL to a file so that it can be
executed by a database administrator who has the sufficient rights.
The following sections contain sample SQL statements needed for creating a backup schema user.
In these examples the backup schema is called archive and the vault schema is corda.
Postgres
The following DDL statements can be used to create a backup schema user archive:
create user archive password 'archive';
create schema archive AUTHORIZATION archive;
grant usage on schema corda to archive;
grant select on all tables in schema corda to archive;
grant insert on all tables in schema corda to archive;
run-migration-scripts command.Oracle
You can use the following DDL statements to create a backup schema user archive:
create user archive identified by archive2 DEFAULT TABLESPACE users QUOTA unlimited ON users;
grant CONNECT, RESOURCE to archive;
Oracle does not have a single grant option to provide rights to all the tables in a schema. This means that rights have to be current on a per table basis.
grant select, insert on corda.NODE_TRANSACTIONS to archive;
The following tables should be archived:
ARCHIVABLE_TXARCHIVABLE_ATTNODE_ATTACHMENTSNODE_TRANSACTIONS
There are also other archivable tables that contain data linked to NODE_ATTACHMENTS and NODE_TRANSACTIONS. An archivable table contains one of the following:
- A column named
transaction_id(meaning it is linked toNODE_TRANSACTIONS). - A column named
att_id(meaning it is linked toNODE_ATTACHMENTS).
Corda provides multiple tables of this type and they vary between different Corda versions. You can also add your own tables. You must grant access to any tables that you want to include in the archiving process.
MSSQL
The following DDL statements can be used to create a backup schema user archive:
create login archive with password = 'Archive123';
create schema archive;
create user archive for login archive with default_schema = archive;
grant SELECT, INSERT, UPDATE, DELETE, VIEW DEFINITION, ALTER, REFERENCES on schema::archive TO archive;
grant CREATE TABLE to archive;
grant CREATE VIEW to archive;
grant SELECT on schema ::corda to archive;
grant INSERT on schema ::corda to archive;
Restarting the node
It is sometimes necessary to restart the node when carrying out an archiving job.
You need to restart the node in the following circumstances:
- Before running import-snapshot, having run ‘delete-snapshot’ (archive schema has been deleted, and now the vault is to be restored from file archive).
- After ‘delete-vault’ has been run using the ‘–record’ option.
- After ‘restore-snapshot’ has been run using the ‘–record’ option.
Archive Service command-line tool
The command-line tool is a ‘fat-jar’ that can be executed directly using the java -jar option.
$ java -jar corda-tools-archive-service-1.0.1.jar --help
archive-service [--config-obfuscation-passphrase[=<cliPassphrase>]]
[--config-obfuscation-seed[=<cliSeed>]]
[--rpc-password[=<rpcPassword>]]
[--rpc-url[=<rpcUrl>]]
[--rpc-user=<rpcUser>]
[--tracker]
[-b=<baseDirectory>]
[-f=<configurationFile>] [COMMAND]
Description:
Command line tool for performing archive operations on the Corda vault.
Options:
-b, --base-directory=<baseDirectory>
Path to the base directory, default current directory
-f, --config-file=<configurationFile>
Path to the configuration file, default node.conf
-t, --tracker Display progress tracking
--config-obfuscation-passphrase[=<cliPassphrase>]
The passphrase used in the key derivation function when generating an AES key
--config-obfuscation-seed[=<cliSeed>]
The seed used in the key derivation function to create a salt
--rpc-user=<rpcUser> Set RPC user
--rpc-password[=<rpcPassword>]
Set RPC user password
--rpc-url[=<rpcUrl>] Set RPC connection URL
-h, --help Show this help message and exit.
-V, --version Print version information and exit.
Commands:
list-jobs display status of archiving jobs
list-items list transactions/attachments for archiving
create-snapshot marks transactions/attachments for archiving
delete-vault delete archived items from the vault
export-snapshot export snapshot to offline storage
delete-snapshot delete the snapshot from backup schema
import-snapshot import an archive to the vault
restore-snapshot restore items from backup schema to the vault
Filters
Filters can be used to limit which transactions and attachments are available for archiving.
They are applied on the command line of the list-items or create-snapshot commands
or alternatively recorded in the CorDapp configuration file.
Each filter has its own configuration requirements, which it takes either from the HOCON file given on the command line or from the CorDapp configuration file.
Custom filters can be implemented by using the Archive Service Library. For more details see the Archive Service Library documentation.
Filter configuration
The following is a sample HOCON configuration file that can be used to configure the standard TransactionId filter.
filter: {
// A list of filters to be applied
filters: [
"TransactionIdFilter"
]
// Configuration for the TransactionIdFilter filter
transactionIdFilter: {
transactions: [
"1234567812345678123456781234567812345678123456781234567812345678"
]
}
}
The following HOCON example can be used to configure the standard Party filter:
filter: {
// A list of filters to be applied
filters: [
"PartyFilter"
]
// Configuration for the PartyFilter filter
partyFilter.parties: [
“O=PartyA,L=London,C=GB”
]
}
Exporters
Exporters are used to copy the archive snapshot from the vault to a permanent archive.
The exporters to be applied can be given on the command line to the export-snapshot command
or recorded in the CorDapp configuration file.
exporter: {
exporters: [
"ZippedFileExporter",
"QueryableStateFileExporter"
]
}
By default no exporters are applied.
Each exporter has its own configuration requirements, which it takes either from the HOCON file given on the command line or from the CorDapp configuration file.
Custom exporters can be implemented for individual archive solutions. For more details see the Archive Service Library documentation.
Queryable state tables
Queryable state tables can be exported to CSV format by listing the tables by listing the tables in
the configuration file under the property queryableTables.
queryableTables: [
"LOAN_STATES"
]
The property can be added to the Archive Service CorDapp configuration file, or passed within the
create-snapshot command configuration.
A suitable exporter, such as QueryableStateFileExporter, must also be listed on the command line to export-snapshot.
Additional tables
Archive Service automatically detects transaction and attachment tables that use the columns
TRANSACTION_ID or ATT_ID within the vault schema and include them in the archive process.
Additional transaction and attachment tables which use different column names can be registered using the
properties additionalTransactionTables and additionalAttachmentTables with the following format:
additionalTransactionTables: [
"ACCOUNT_STATE:TX_ID",
]
additionalAttachmentTables: [
"ATTACHMENT_INFO:ATTACHMENT_ID"
]
Data from these tables will be recorded as part of the snapshot process and later deleted from the vault, but will not be exported to permanent archive.
Tables should be excluded from the archive process can be registered using the
properties excludeTransactionTables and excludeAttachmentTables.
Was this page helpful?
Thanks for your feedback!
Chat with us
Chat with us on our #docs channel on slack. You can also join a lot of other slack channels there and have access to 1-on-1 communication with members of the R3 team and the online community.
Propose documentation improvements directly
Help us to improve the docs by contributing directly. It's simple - just fork this repository and raise a PR of your own - R3's Technical Writers will review it and apply the relevant suggestions.
We're sorry this page wasn't helpful. Let us know how we can make it better!
Chat with us
Chat with us on our #docs channel on slack. You can also join a lot of other slack channels there and have access to 1-on-1 communication with members of the R3 team and the online community.
Create an issue
Create a new GitHub issue in this repository - submit technical feedback, draw attention to a potential documentation bug, or share ideas for improvement and general feedback.
Propose documentation improvements directly
Help us to improve the docs by contributing directly. It's simple - just fork this repository and raise a PR of your own - R3's Technical Writers will review it and apply the relevant suggestions.