Architecture for Cluster Administrators

This section describes Corda 5 from the perspective of a Corda cluster Administrator. If you are new to Corda, refer to Corda Fundamentals to familiarize yourself with the key concepts. If you are familiar with Corda 4, remember that while Corda 5.1 is an evolution of Corda, it is quite different from an infrastructure and administration point of view.
Corda 5 is a distributed application made of multiple stateless workers, as described in the Workers section. The following sections examine the core technologies that underpin Corda:
Persistence
Corda uses relational databases for its persistence layer. Corda uses a number of databases which can be co-hosted on the same database server or even share a single database instance but segregated by schemas. All are logically separated, with Corda managing the connection details for each of the logical databases.
Broadly speaking, there are two groups of databases:
- Cluster-wide databases — contain data that is necessary for the running of the Corda cluster.
- Virtual node databases — contain data that is specific to a particular virtual node The combination of the context of a user and the ephemeral compute instances created to progress a transaction on that identity's behalf. .
The following diagram provides a high-level overview of the Corda databases:
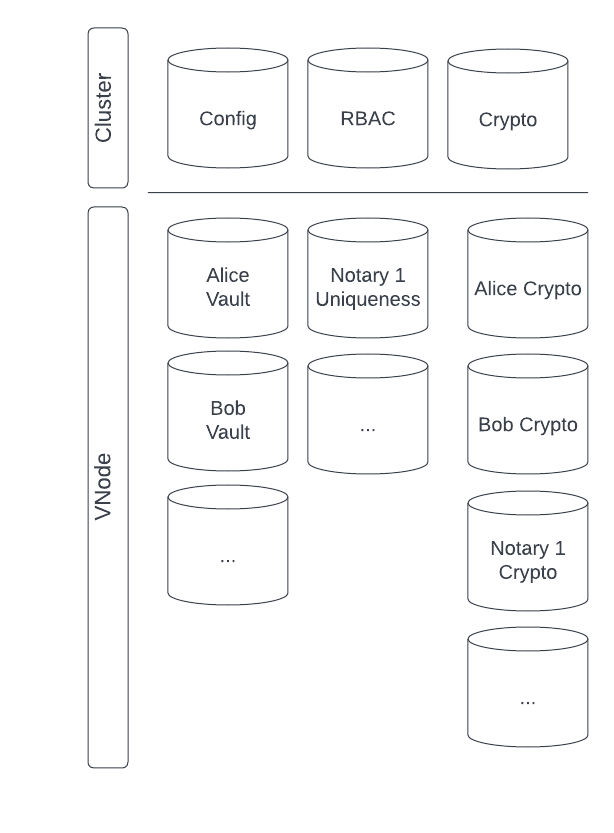
Cluster Databases
Config— contains data that is used to support the general operation of the cluster, such as data about CorDapps Corda Distributed Application. A Java (or any JVM targeting language) application built using the Corda build toolchain and CorDapp API to solve some problem that is best solved in a decentralized manner. , worker configuration, and virtual node metadata.RBAC Role-based access control. Also known as role-based security. A permission system to restrict system access based on assigned permissions.(Role Based Access Control) — contains the data used for User Access Control. Currently, this is used for authorization of the REST API.Crypto— contains (encrypted) cryptographic key material that is used for cluster-wide operations.
Virtual Node Databases
Corda requires one of each of the following types per virtual node:
Vault— contains the virtual node ledger data as well as data defined in CorDapp custom schemas.Crypto— contains the virtual node (encrypted) cryptographic key material such as ledger keys A key which can be used to sign for transactions. This key may be held confidentially and signatures may be used as evidence of authority to sign transactions. Alternatively, it may be published in the virtual nodes's MemberInfo to act as a published fact to prove the identity of the virtual node on the ledger. .Uniqueness(optional) — maintains a record of unspent and spent states An immutable object representing a fact known by one or more participants at a specific point in time. You can use states to represent any type of data, and any kind of fact. generated as part of UTXO Unspent Transaction Output. The unspent output of a cryptocurrency transaction, representing the amount of digital currency that has not been spent and is available for use in future transactions. ledger transactions. This is only relevant for notary Corda’s uniqueness consensus service. The notary’s primary role is to prevent double-spends by ensuring each transaction contains only unique unconsumed input states. nodes.
Database Management
All cluster-level databases must be initialized before Corda is operational. See the Corda Deployment section for information about how databases are bootstrapped. Once the databases are created, Corda must be aware of where the dependent databases are. This happens in two places:
Configdatabase — the connection details for the config database are passed into all instances of the database worker A worker that connects to, manages, and operates upon the database(s) used by the Corda cluster. This includes the cluster-level database schemas needed to store configuration data for the cluster, but also the separate databases/schemas used by each virtual node. when it is started. A read-only connection to this database must also be passed into the crypto worker A worker that manages the cryptographic materials of the Corda cluster and virtual nodes. It connects to any Hardware Security Modules (HSM) used to hold private keys, as well as database(s) used as a software HSM to hold wrapped and encrypted private keys. to enable it to read crypto database configuration.- All other databases — connection details for all other databases are stored in a table inside the
Configdatabase.
This design enables Corda to connect to a dynamic set of databases, specifically the virtual node databases, which are created and managed by Corda itself. Virtual node databases are automatically created when a new virtual node is created. A future version may include functionality that allows a Cluster Administrator to create and manage virtual node databases outside of Corda.
Because database connection details, including credentials, are stored inside the config database, we suggest passwords, and other sensitive configuration values, are treated as “secrets”. For more information, see Configuration Secrets.
Key Management
Corda requires the following types of keys:
- P2P
- P2P Session initiation
- MGM
- Notary
- Ledger
- CorDapp publisher code signing
For a list of the keys and certificates used by Corda, see the Reference section.
Key Wrapping
All keys are stored in the Crypto databases (cluster and virtual nodes) and they are all encrypted at rest with “wrapping keys”:
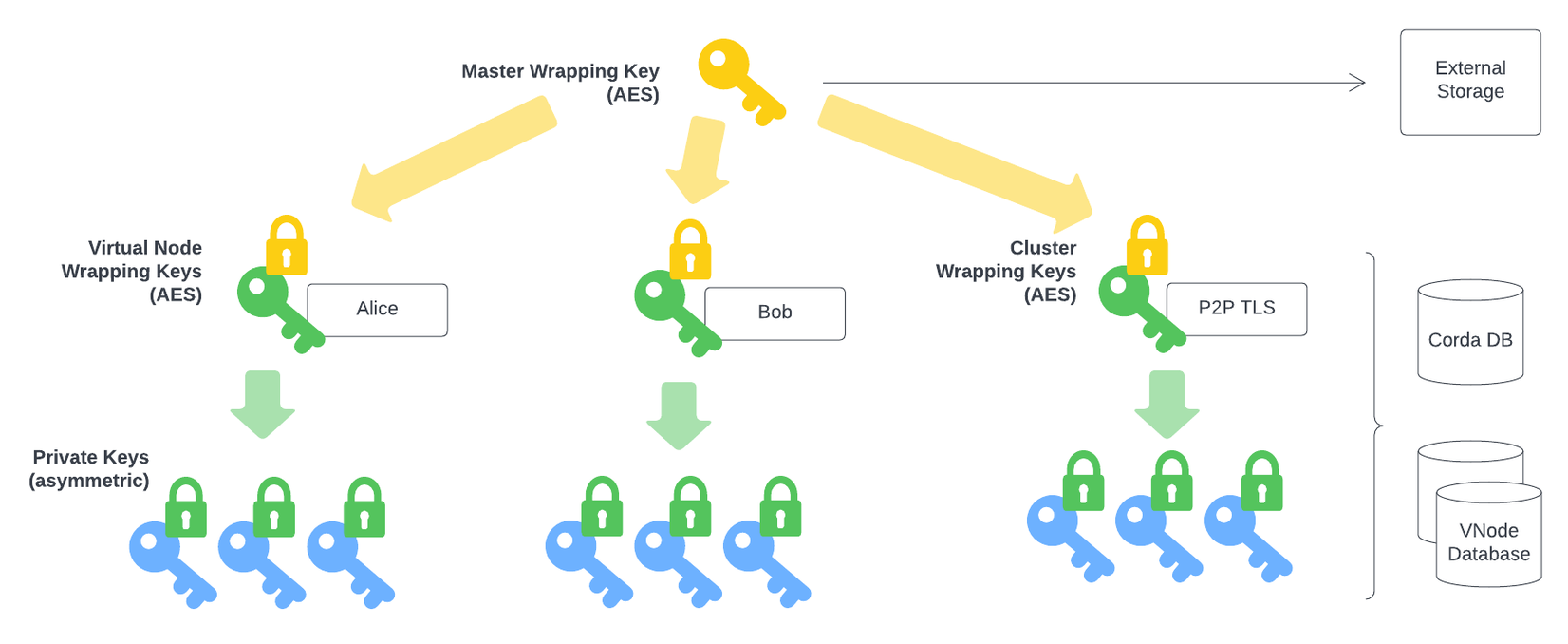
The diagram illustrates that key wrapping is hierarchical. The master wrapping key protects other wrapping keys, such as the virtual node related keys, which in turn protect the private keys used by Corda. It must never be possible for someone with a copy of the Corda database, or a virtual node database, to decrypt the keys stored in the database using other information stored in the database. Therefore, the master wrapping key, or the information required to generate this key, must be stored and managed outside Corda. This can be achieved in one of the following ways:
- Pass a passphrase and salt, to generate the master key, into the crypto worker processes. For more information, see Default Secrets Service.
 Store and manage the master in an external key management system that Corda retrieves when required. For more information, see External Secrets Service.
Store and manage the master in an external key management system that Corda retrieves when required. For more information, see External Secrets Service.
Kafka
Corda uses Apache Kafka internally as a message bus and also to emit events from flow Communication between participants in an application network is peer-to-peer using flows. code. For more information see:
Load Balancers
A standard HTTP load balancer can be used to balance the load between all REST API workers. For information about configuring your load balancer, see the Deploying section.
Java/JVM
All Corda components are hosted in a JAVA 17 compatible JVM. Azul Zulu 17 is currently the only supported and tested JVM, and is distributed with the Corda container images.
Observability
Logging
All components in a Corda cluster produce logs at level INFO by default. These are sent to stdout/stderr and can easily be integrated with a log collector or aggregator of choice. All application-level logging is handled by Log4J which means the log level and target can be changed through customizing the Log4J config.
For more information about retrieving logs from Kubernetes A powerful tool for managing containerized applications at scale, making it easier for teams to deploy and manage their applications with high reliability and efficiency. , see Metrics.
Metrics
Corda workers expose metrics to provide a better insight into the system as a whole. These metrics are exposed as Prometheus-compatible HTTP endpoints that can be consumed by a collector and visualization tool of choice. For more information, see Metrics.
Was this page helpful?
Thanks for your feedback!
Chat with us
Chat with us on our #docs channel on slack. You can also join a lot of other slack channels there and have access to 1-on-1 communication with members of the R3 team and the online community.
Propose documentation improvements directly
Help us to improve the docs by contributing directly. It's simple - just fork this repository and raise a PR of your own - R3's Technical Writers will review it and apply the relevant suggestions.
We're sorry this page wasn't helpful. Let us know how we can make it better!
Chat with us
Chat with us on our #docs channel on slack. You can also join a lot of other slack channels there and have access to 1-on-1 communication with members of the R3 team and the online community.
Create an issue
Create a new GitHub issue in this repository - submit technical feedback, draw attention to a potential documentation bug, or share ideas for improvement and general feedback.
Propose documentation improvements directly
Help us to improve the docs by contributing directly. It's simple - just fork this repository and raise a PR of your own - R3's Technical Writers will review it and apply the relevant suggestions.