Collaborative Recovery V1.2.1
Who this documentation is for:
- Node operators
- Business Network Operators (BNOs)
- Corda developers
Introducing Collaborative Recovery V1.2.1

Collaborative Recovery is a secure, privacy-oriented solution that helps you identify and retrieve data if you ever encounter a disaster recovery (DR) scenario on your Business Network.
Once you have installed the Collaborative Recovery CorDapps, you can safely use Collaborative Recovery to detect potential ledger inconsistencies and recover any missing data from parties you have transacted with. Designed to ensure the continued security and privacy of Corda, this feature runs in the background, acting as an additional layer of security when using Corda.
As the name suggests, this is a collaborative method for recovering data. For maximum peace of mind, you should seek agreement across your Business Network to make this feature part of the overall disaster recovery policy.
Before installing and using the Collaborative Recovery CorDapps, you need to know:
- Your Business Network disaster recovery policy.
- The Corda platform requirements.
- How and when the LedgerSync and LedgerRecover CorDapps should be used.
In this version
You can now use the skipSizeQuery configuration in LedgerRecover in cases where you cannot grant SELECT permission by the PostgreSQL admin to check the file size of the exported transactions before exporting them. This check normally verifies that the size of files to be exported does not exceed your node’s disk size.
This change does not remove the file size limit from a network, so if the exported transactions do exceed your node’s disk size, the recovery operation can still fail. In this case, you will get a generic error from Corda, rather than a specific reason for the recovery failure.
Changes in V1.2
In Collaborative Recovery V1.2, LedgerSync has been modified to be compatible with the Archive Service.
Changes from V1.0 to V1.1
Collaborative Recovery 1.1 now makes use of LedgerGraph as a stand-alone CorDapp to get in-memory access to transaction data. In V 1.0, this was bundled with the other Collaborative Recovery CorDapps. Support for Confidential Identities has been moved from LedgerSync to LedgerGraph CorDapps.
Main stages of Collaborative Recovery
There are seven stages in the Collaborative Recovery process. You should perform steps 1-3 as a precaution. The rest only need to be performed in the unlikely event of a disaster recovery situation:
- Agree to add and enforce Collaborative Recovery at the Business Network level.
- Validate the nodes you may transact with by creating wrapping flows for Collaborative Recovery CorDapp flows.
- Monitor for inconsistencies in your node’s data. You do this by scheduling regular reconciliation flows using the LedgerSync CorDapp.
- In a disaster recovery scenario, follow your agreed disaster recovery policy. Try to recover data using backups first.
- If your other procedures cannot recover your data, initiate data recovery flows using:
- LedgerRecover (Automatic) for automatic data recovery. Usually, this is most effective when there is only a minor loss of data.
- LedgerRecover (Manual) for manual data recovery. In this path, you need to manually export and import data back onto the network.
- Validate that the data has been recovered.
- Review the disaster recovery policy.
When to use Collaborative Recovery
Collaborative Recovery is a last-resort option to recover your data. Whilst it provides tools to detect and recover missing ledger data, it’s not sufficient as a disaster recovery strategy on its own. You must use Collaborative Recovery in conjunction with conventional disaster recovery strategies, such as backups and replication.
Ideally, you should never need to use Collaborative Recovery. To protect the data on your node, each node you transact with should be part of a robust disaster recovery plan, agreed at the Business Network level. This strategy should mean you have backups include the following:
- Full and incremental database backups.
- Synchronous database replication.
- Replicated and fault-tolerant filesystem (to prevent loss of MQ data).
If your Business Network is not supported by synchronous database replication on all nodes, but uses asynchronous replication combined with incremental backups instead, you do not have a 100% recovery guarantee in a disaster scenario. By definition, the data in your asynchronous replica is behind the master node.
If you find yourself in this position, or if your other disaster recovery procedures fail, Collaborative Recovery can help you restore and synchronise data across the ledger.
Who can use Collaborative Recovery
Collaborative Recovery applications have a minimum platform version of 6 and are compatible only with Corda Enterprise nodes.
Collaborative Recovery is an Enterprise, CorDapp-level solution and is not shipped as a part of Corda itself. Only nodes that have the Collaborative Recovery CorDapps installed can participate in Collaborative Recovery. In mixed networks that consist of both Open Source and Enterprise nodes, only the Enterprise nodes of the right version that have the Collaborative Recovery CorDapps installed will be able to participate in Collaborative Recovery.
Scope of Collaborative Recovery
Collaborative Recovery allows Corda nodes to retrieve missing ledger data from other peers on the network. This means that only data that was shared in the first place can be recovered. You can use Collaborative Recovery to recover the following assets:
- Transactions.
- Attachments.
- Historical network parameters.
Out-of-scope assets
You cannot recover these assets using Collaborative Recovery:
- Confidential identities. By definition, private keys can’t be recovered from other peers. The states that belong to those keys can, however, be recovered if the proof of owning the key was shared with the counterparty when the transaction happened.
- Node identity / TLS keys.
- Node and CorDapp configuration files.
- CorDapp jars.
- MQ data.
- Self-issued but never transacted states. However, such states can be unilaterally reissued onto the ledger, as issuances don’t require notarization.
- Off-ledger tables.
- Observed transactions. Transactions that have been shared as a part of Observers functionality have to be re-provisioned separately.
- Scheduled states.
- Any ledger data that has been shared with parties that are not available on the network anymore.
Out-of-scope RPO and RTO guarantees
Due to the nature of decentralised systems, Collaborative Recovery cannot provide Recovery Point Objective (RPO) and Recovery Time Objective (RTO) guarantees.
The amount of data that can be recovered cannot be guaranteed in cases where the data is not exclusively under the control of a single operator. For example, some data might be unrecoverable due to a counterparty not being a part of the network anymore.
The amount of time required for recovery can’t be guaranteed as peers might be temporarily unavailable or have low bandwidth.
Collaborative Recovery policies that mandate the SLAs for the participants’ nodes to respond to the disaster recovery requests should be enforced at the Business Network governance level.
Overview of the Collaborative Recovery CorDapps
Collaborative Recovery is made up of two CorDapps - LedgerSync and LedgerRecover. These are used together to reconcile and recover lost data.
LedgerGraph
LedgerGraph is a CorDapp used to get in-memory access to transaction data. Transaction information is kept in a graph structure on any node where LedgerGraph is installed. As not all transactions are related to all other transactions, it can actually contain multiple components (or sub-graphs): each a directed acyclic graph (DAG).
LedgerSync
LedgerSync is a CorDapp that safely and privately highlights the differences between the common ledger data held by two nodes in the same Business Network. A peer running the CorDapp can be alerted to missing transactions. This procedure is called Reconciliation.
LedgerSync has been designed to efficiently reconcile large sets of data with a small amount of difference or no differences at all (based on Efficient Set Reconciliation Algorithm Without Prior Context). Generally speaking, the amount of data you can expect to transfer is proportional to the size of the difference and not the total number of items in the data set. For this reason, LedgerSync introduces only a minimal network overhead, even for a large data set.
LedgerSync has been designed with privacy in mind. Parties never share any real data. Instead, they share Invertible Bloom Filters that contain obfuscated data only and can’t be decoded by a party unilaterally. Furthermore, LedgerSync prevents privacy leaks by allowing only parties that participated in a transaction to report that the transaction is missing from the initiator’s ledger.
LedgerSync can operate on a schedule as well as on demand. It utilises bounded flow pools to limit the number of concurrent inbound / outbound reconciliations and also supports different throttling techniques to prevent the functionality from being abused.
A high-level, peer-to-peer reconciliation flow is depicted in the diagram below. LedgerSync can run multiple reconciliations concurrently, up to the limit configured by the user.
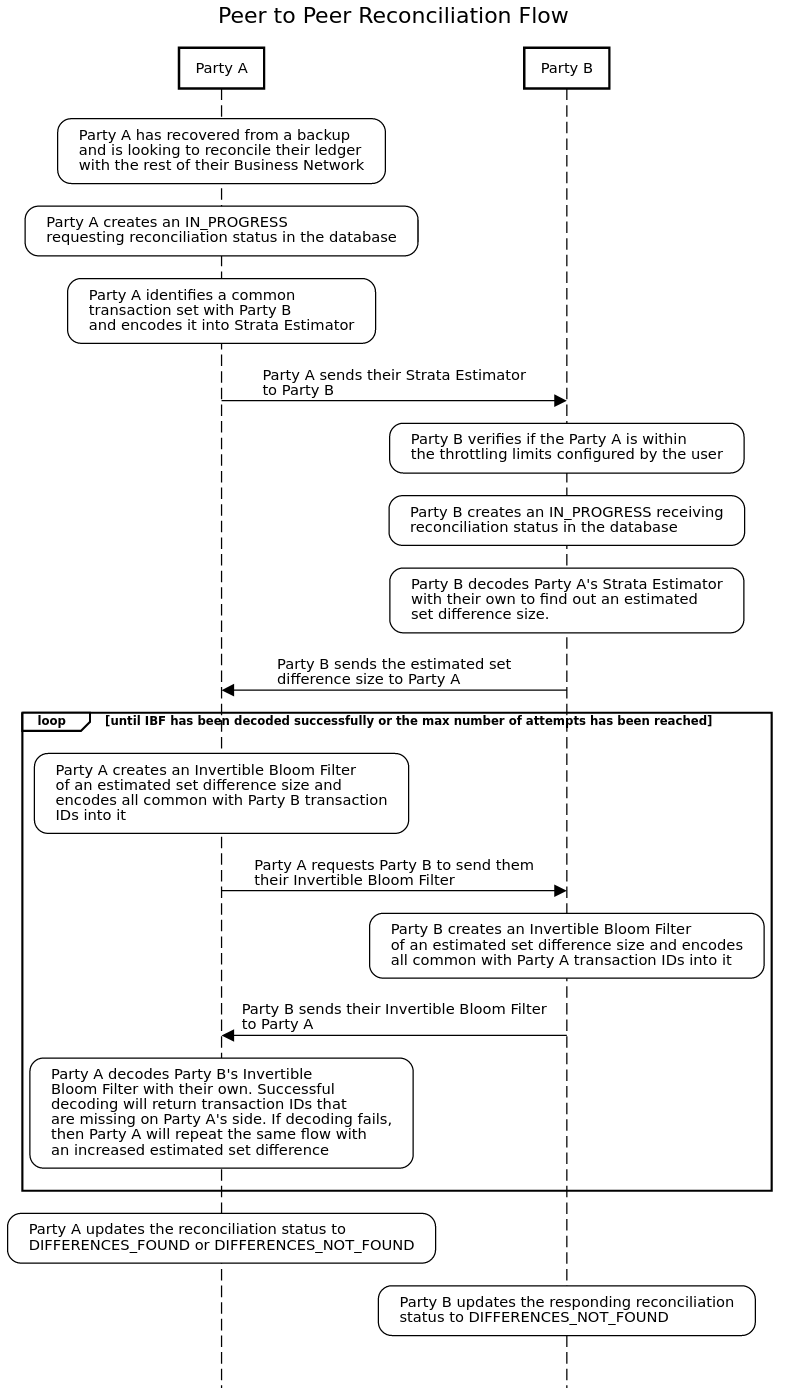
LedgerRecover
LedgerRecover helps to recover missing transactions, attachments and network parameters based on the outputs of LedgerSync. LedgerRecover can be operated in automatic and manual modes.
LedgerRecover (Automatic)
LedgerRecover (Automatic) has been designed to recover small amounts of ledger data that would have little to no impact
on the responding node’s performance. LedgerRecover (Automatic) is built on top of Corda’s SendTransactionFlow and ReceiveTransactionFlow.
These flows handle resolution of attachments, network parameters, and transaction backchains out-of-the-box. Before entering recovery,
the responder verifies the eligibility of the requester seeing the requested transactions.
Only transactions and backchains where both counterparties are participants will be allowed for recovery. LedgerRecover (Automatic) supports different types of throttling to prevent accidental abuse of the functionality.
A high-level, peer-to-peer automatic recovery flow is depicted in the diagram below.
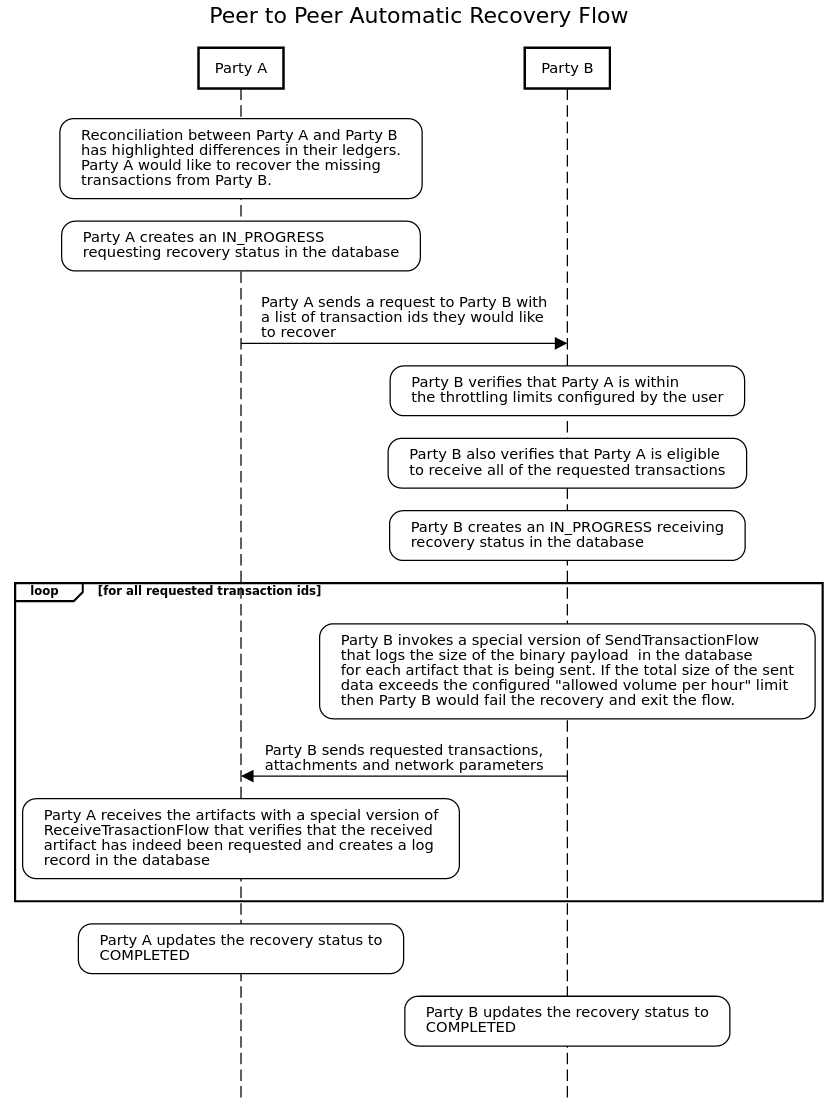
LedgerRecover (Manual)
LedgerRecover (Manual) has been designed for larger volumes of data and for cases where the recovery request requires manual approval. During a manual recovery flow, an initiating party would make a request to kick off a manual recovery process. Each party (the initiator and responder) persists a record of this request. The responder then manually investigates the recovery request, exports the data to the filesystem, and passes it to the requester. The process of passing data to the requester must be carried out off-ledger without relying on the Corda messaging layer, after which the requester would manually import the data into their vault.
LedgerRecover (Manual) ensures ledger consistency - importing data would not lead to an inconsistent ledger even if the import has been stopped halfway through.
A high-level, peer-to-peer manual recovery flow is depicted in the diagram below.
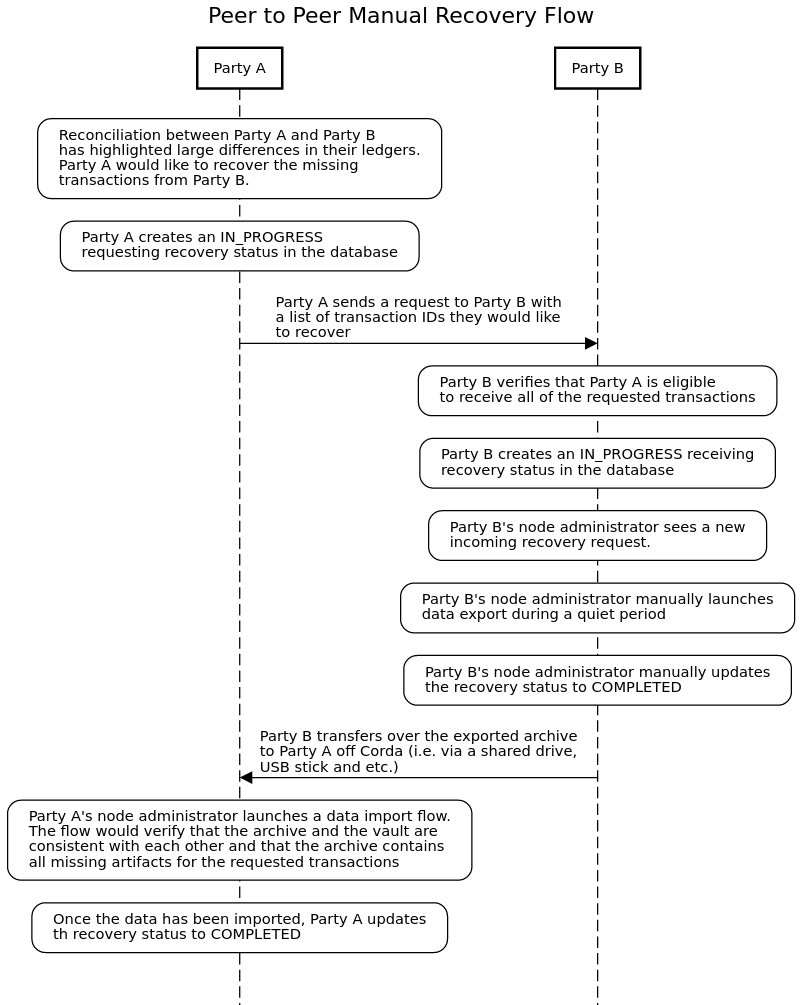
Supported disaster recovery scenarios
LedgerSync and LedgerRecover can only support cases when the ledger is self-consistent, so there can be no holes or broken references within the chain of transactions. If you restore from a backup, that should roll your ledger back to a self-consistent state. For example, this might happen when a transaction has not reached the node due to the issues with the infrastructure or when the node has been recovered from a backup that was behind the current state of the network.
Scenarios such as when a node’s database is manually tampered with are not fully supported in Version 1.2.
Compatibility with other Corda Enterprise libraries
If you are using other R3 Corda Enterprise libraries, you may need to take extra steps to ensure Collaborative Recovery will work if it is ever needed.
Tokens SDK - fully compatible
Collaborative Recovery is fully compatible with the Tokens SDK.
Accounts SDK - compatible with limitations
You can use Collaborative Recovery to recover transactions where a node participated through an identity created with the Accounts SDK, with a few significant limitations.
When using Accounts, remember that each account is still represented by a Confidential Identity. Even though the transactions that the account has participated in are recoverable (given that the AccountInfo has been shared alongside the transactions), the account key pair itself won’t be recovered from other peers.
You need to implement your own key rotation techniques to move the states to a different key if the original one has been lost.
It is currently not possible to recover the issuance transaction containing an AccountInfo state (generated when a new Account is created on a node). The AccountInfo transaction is required for Account balances, issuances and payments to work properly. Any Account that has lost the corresponding AccountInfo transaction can no longer be considered functional.
Finance - not compatible
Collaborative Recovery is not compatible with the legacy Corda Finance module. This is due to the way Confidential Identities are used as a part of the CashPaymentFlow.
In general, R3 recommends that you avoid the legacy Corda Finance module in favour of Tokens and Accounts SDKs.
Was this page helpful?
Thanks for your feedback!
Chat with us
Chat with us on our #docs channel on slack. You can also join a lot of other slack channels there and have access to 1-on-1 communication with members of the R3 team and the online community.
Propose documentation improvements directly
Help us to improve the docs by contributing directly. It's simple - just fork this repository and raise a PR of your own - R3's Technical Writers will review it and apply the relevant suggestions.
We're sorry this page wasn't helpful. Let us know how we can make it better!
Chat with us
Chat with us on our #docs channel on slack. You can also join a lot of other slack channels there and have access to 1-on-1 communication with members of the R3 team and the online community.
Create an issue
Create a new GitHub issue in this repository - submit technical feedback, draw attention to a potential documentation bug, or share ideas for improvement and general feedback.
Propose documentation improvements directly
Help us to improve the docs by contributing directly. It's simple - just fork this repository and raise a PR of your own - R3's Technical Writers will review it and apply the relevant suggestions.