Deploy and operate Collaborative Recovery V1.2.1
Who this documentation is for:
- Node operators
- Business Network Operators (BNOs)
- Corda developers
You can use the Collaborative Recovery CorDapps to automate the process of recovering or reconciling data in a disaster recovery scenario. Follow this guide to help you establish effective schedules for data reconciliation, and best practices for retrieving data in the unlikely event of a disaster.
Schedule reconciliation

If you and counterparties on your Business Network (BN) plan to use collaborative recovery as part of your disaster planning, it’s a good idea to schedule regular reconciliation checks using the LedgerSync CorDapp. You can achieve this by implementing a small layer to schedule and integrate ledger syncing with your Business Network services. For practical steps on scheduling recovery, use the LedgerSync guide.
How frequently you should run reconciliation checks depends on the size of your network. Since reconciliation flows carry some memory overheads, smaller networks may be able to schedule more regular reconciliation actions. For a larger network, you can implement a lighter schedule of reconciliations, or you could choose to reconcile more regularly, but with a random subset of available peers. This would give you an indication of the general health of data in the BN.
Since some recovery flows have been designed to be run manually, you can set alerts that tell you when reconciliation differences occur. When you receive the alert, you can implement manual recovery with each of the highlighted parties.
Monitor reconciliation and receive alerts using metrics
The Collaborative Recovery CorDapps expose a number of JMX metrics via Jolokia. You can see the full list of the exposed metrics for LedgerSync here, and LedgerRecover here. These are exposed alongside metrics from the node. You can also monitor via Jolokia.
As part of your disaster recovery strategy, you can set up alerts for LedgerSync’s NumberOfFailedReconciliations and NumberOfReconciliationsWithDifferences metrics.
During normal operations, values for both of these metrics should be equal to zero.
NumberOfFailedReconciliations
The NumberOfFailedReconciliations metric shows how many reconciliations have failed during the last run.
If the value is not zero, then the operator should first obtain a list of parties whose reconciliations have failed via the FailedParties metric.
Then for each of the failed parties, fetch their status via the ReconciliationStatus metric and investigate the failure reason.
For example, a reconciliation might fail due to the counterparty not having the Collaborative Recovery CorDapps installed on
their node or the counterparty’s node might be too busy to reply to the reconciliation requests.
Each failure needs to be investigated and resolved separately.
Once this is done, the metric value will be reset to zero during the next reconciliation cycle.
NumberOfReconciliationsWithDifferences
The NumberOfReconciliationsWithDifferences metric shows how many reconciliations have highlighted actual differences.
If this value is not zero, it might potentially mean that the node’s ledger is in an inconsistent state.
Please refer to the following sections for the procedure to follow.
Database operations
Collaborative Recovery CorDapps rely on the following database tables:
- LedgerSync:
CR_RECONCILIATION_STATUS
- LedgerRecover:
CR_RECOVERY_REQUESTCR_RECOVERY_LOG
The database tables are managed via Liquibase migration scripts that are shipped as a part of the Collaborative Recovery CorDapps.
Collaborative Recovery CorDapps are compatible with the full range of the databases supported by Corda Enterprise.
The contents of the Collaborative Recovery tables should not be altered manually. The tables are not envisioned to grow large in size. The space complexities are outlined below:
CR_RECONCILIATION_STATUS- O(Number of participants in Business Network).CR_RECOVERY_REQUEST- O(Number of incoming / outgoing recovery attempts).CR_RECOVERY_LOG- O(Number of sent / recovered transactions, attachments and network parameters).
Suggested setup for disaster recovery
You can see a suggested high-level, disaster recovery setup in the diagram below.
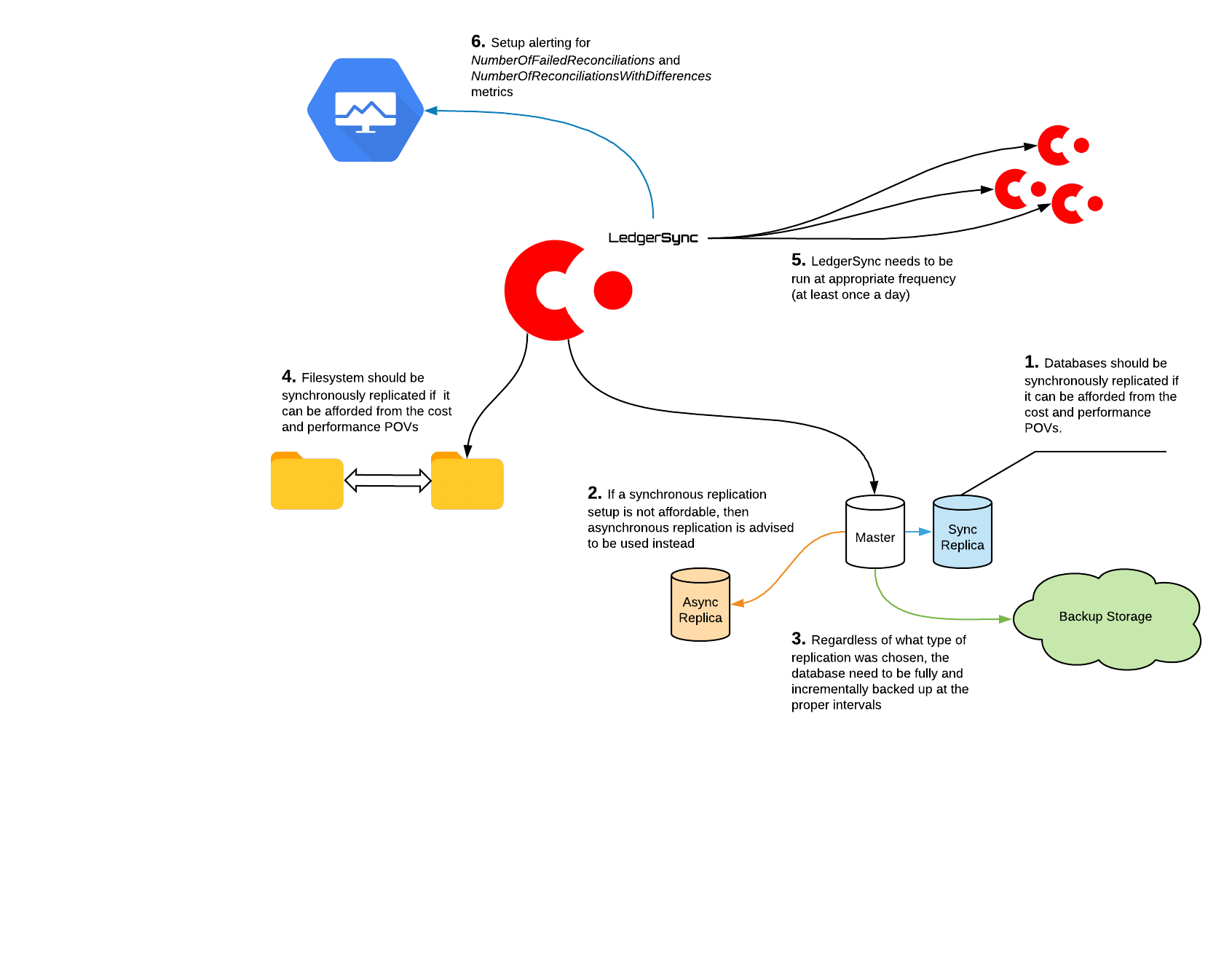
The exact setup you choose is likely to be influenced by your organisation and business requirements, but the key points are:
- Whenever possible, you should use synchronous replication for both database and filesystem.
- If synchronous replication is not an option, consider using asynchronous replication, which is usually cheaper and faster.
- Make full and incremental database backups at an appropriate schedule.
- Run LedgerSync at appropriate intervals.
- Set up alerting for the
NumberOfFailedReconciliationsandNumberOfReconciliationsWithDifferencesmetrics as explained in the previous section.
Suggested procedure for disaster recovery
The exact procedure you follow is likely to be unique to your organisation. This section helps you see how to confirm that the ledger is consistent and operational, so if you ever need to implement recovery, you have a clear idea of the scale of recovery needed.
In the absence of synchronous replication
If you have not been able to use synchronous replication:
- After recovering from a backup/asynchronous replica, some of the flow checkpoints may be stale, and resuming them might cause disruption.
- In an ideal scenario, all flow checkpoints should be cleaned out manually before starting the node. You can do this using Corda checkpoint tooling.
- Message queue files should also be cleaned manually, as they are unlikely to match the contents of the database anymore, especially when restoring from a backup.
- After the node has been started, you should run LedgerSync to check whether the ledger is missing any transactions.
What to do if ledger inconsistencies are detected
In rare circumstances, the NumberOfReconciliationsWithDifferences metric may show a false positive. For example, a false positive may arise if a transaction is still in flight at one side when the reconciliation is run.
Before taking any further action, you should run RefreshReconciliationStatusesFlow via the node’s shell to synchronise reconciliation statuses with the vault.
If, after that, the metric has not zeroed out, further action is needed.
Inconsistencies in the ledger can indicate some serious underlying issues. If there is no obvious reason for them to occur, such as recovering from a backup, then follow these steps:
Verify whether there are any issues with the underlying messaging infrastructure.
Check the node’s logs for errors.
Analyse the node’s database for stuck flow checkpoints.
Verify whether the node’s database has been tampered with manually, or has run out of space.
After diagnosing the disaster, you may need to trigger the standard Disaster Recovery protocol defined by your organisation.
Once the issue has been debugged and understood, you can recover the missing transactions from other parties on a peer-to-peer basis. The list of missing transaction IDs can be obtained from the
lastSuccessfulReconciliationStatusfield of a reconciliation status.lastSuccessfulReconciliationStatusis a binary field and can be decoded using Corda Blob Inspector.Depending on the size of the difference, either manual or automatic recovery can be used. Consider using automatic LedgerRecover and switch to manual if automatic fails because there have been too many transactions or too frequent recovery requests.
When you use manual recovery, it creates unencrypted archives with transaction data in clear-text on the filesystem of the party that supplies the data. If the requesting and responding parties have confidentiality requirements, you should both follow best practices to ensure the data doesn’t fall into the wrong hands. At a minimum, we advise to use encrypted and secure storage to transmit the data (or encrypt the data on the supplier side) as well as delete the archive data from the responder and initiator filesystems.
Statuses of running recoveries can be monitored via LedgerRecover metrics. At the end of each recovery, the relevant reconciliation data is refreshed automatically by the recovery flows. This removes all transactions that now exist in the vault. If you are in a situation where more loss of data is expected, you can re-run reconciliation to confirm that the differences are gone.
When using Collaborative Recovery, keep in mind:
- The database backups and replicas should be the first port of call for recovering the vast majority of the ledger data.
- Self-issued private keys for Confidential Identities keys can’t be recovered from other peers.
- Self-issued and never transacted states can’t be recovered from other peers and need to be re-issued separately.
- Any off-ledger data (not to be confused with State Schemas) cannot be recovered from other peers.
Business Network Operator involvement and responsibilities
Collaborative Recovery supports the resiliency of Corda nodes operating as part of a Business Network (BN). This means:
- It is distributed as a CorDapp-level solution rather than being included in the Corda protocol.
- It has been designed based on the assumption that the Business Network Operator (BNO) will assume some responsibilities in co-ordinating reconciliation and recovery activities across the network.
As a BNO planning to use Collaborative Recovery as part of your disaster recovery strategy, you are expected to:
- Distribute the Collaborative Recovery CorDapps to all peers (if the BNO is also the developer of the business application(s) run by peers on the network, they might distribute them in a single bundle alongside the Collaborative Recovery CorDapps)
- Make sure that all peers on the network use compatible version(s) of the Collaborative Recovery CorDapps
- Coordinate scheduled reconciliation times (for example, making sure they happen during expected daily downtime to minimise load on the network)
It’s important to note that if any node on a BN is not running the Collaborative Recovery CorDapps, all other nodes will not be able to recover ledger data from it. This undermines the effectiveness of the Collaborative Recovery CorDapps - the only way to ensure successful recovery is to enforce that all participants run the apps in production.
Was this page helpful?
Thanks for your feedback!
Chat with us
Chat with us on our #docs channel on slack. You can also join a lot of other slack channels there and have access to 1-on-1 communication with members of the R3 team and the online community.
Propose documentation improvements directly
Help us to improve the docs by contributing directly. It's simple - just fork this repository and raise a PR of your own - R3's Technical Writers will review it and apply the relevant suggestions.
We're sorry this page wasn't helpful. Let us know how we can make it better!
Chat with us
Chat with us on our #docs channel on slack. You can also join a lot of other slack channels there and have access to 1-on-1 communication with members of the R3 team and the online community.
Create an issue
Create a new GitHub issue in this repository - submit technical feedback, draw attention to a potential documentation bug, or share ideas for improvement and general feedback.
Propose documentation improvements directly
Help us to improve the docs by contributing directly. It's simple - just fork this repository and raise a PR of your own - R3's Technical Writers will review it and apply the relevant suggestions.