Release new CorDapp versions
CorDapp versioning

The Corda platform does not mandate a version number on a per-CorDapp basis. Different elements of a CorDapp are allowed to evolve separately:
- States
- Contracts
- Services
- Flows
- Utilities and library functions
- All, or a subset, of the above
Sometimes, however, a change to one element will require changes to other elements. For example, changing a shared data structure may require flow changes that are not backwards-compatible.
Areas of consideration
This document will consider the following types of versioning:
- Flow versioning
- State and contract versioning
- State and state schema versioning
- Serialization of custom types
Flow versioning
Any flow that initiates other flows must be annotated with the @InitiatingFlow annotation, which is defined as:
annotation class InitiatingFlow(val version: Int = 1)
The version property, which defaults to 1, specifies the flow’s version. This integer value should be incremented
whenever there is a release of a flow which has changes that are not backwards-compatible. A non-backwards compatible
change is one that changes the interface of the flow.
What defines the interface of a flow?
The flow interface is defined by the sequence of send and receive calls between an InitiatingFlow and an
InitiatedBy flow, including the types of the data sent and received. We can picture a flow’s interface as follows:
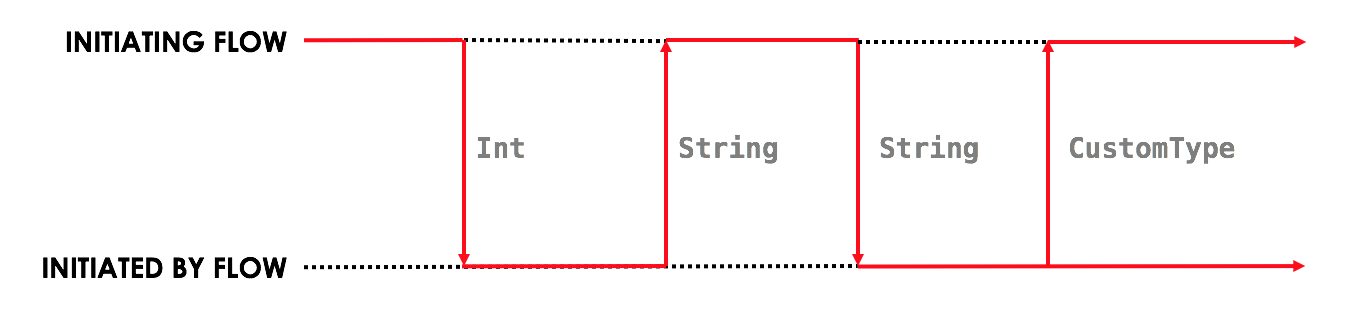
InitiatingFlow:
- Sends an
Int - Receives a
String - Sends a
String - Receives a
CustomType
The InitiatedBy flow does the opposite:
- Receives an
Int - Sends a
String - Receives a
String - Sends a
CustomType
As long as both the InitiatingFlow and the InitiatedBy flows conform to the sequence of actions, the flows can
be implemented in any way you see fit (including adding proprietary business logic that is not shared with other
parties).
What constitutes a non-backwards compatible flow change?
A flow can become backwards-incompatible in two main ways:
The sequence of
sendandreceivecalls changes:- A
sendorreceiveis added or removed from either theInitiatingFloworInitiatedByflow - The sequence of
sendandreceivecalls changes
- A
The types of the
sendandreceivecalls changes
What happens when running flows with incompatible versions?
Pairs of InitiatingFlow flows and InitiatedBy flows that have incompatible interfaces are likely to exhibit the
following behaviour:
- The flows hang indefinitely and never terminate, usually because a flow expects a response which is never sent from the other side
- One of the flow ends with an exception: “Expected Type X but Received Type Y”, because the
sendorreceivetypes are incorrect - One of the flows ends with an exception: “Counterparty flow terminated early on the other side”, because one flow sends some data to another flow, but the latter flow has already ended
How do I upgrade my flows?
- Update the flow and test the changes. Increment the flow version number in the
InitiatingFlowannotation. - Ensure that all versions of the existing flow have finished running and there are no pending
SchedulableFlowson any of the nodes on the business network. This can be done by draining the node (see below). - Shut down the node.
- Replace the existing CorDapp JAR with the CorDapp JAR containing the new flow.
- Start the node.
If you shut down all nodes and upgrade them all at the same time, any incompatible change can be made.
In situations where some nodes may still be using previous versions of a flow and thus new versions of your flow may talk to old versions, the updated flows need to be backwards-compatible. This will be the case for almost any real deployment in which you cannot easily coordinate the roll-out of new code across the network.
How do I ensure flow backwards-compatibility?
The InitiatingFlow version number is included in the flow session handshake and exposed to both parties via the
FlowLogic.getFlowContext method. This method takes a Party and returns a FlowContext object which describes
the flow running on the other side. In particular, it has a flowVersion property which can be used to
programmatically evolve flows across versions. For example:
@Suspendable
override fun call() {
val otherFlowVersion = otherSession.getCounterpartyFlowInfo().flowVersion
val receivedString = if (otherFlowVersion == 1) {
otherSession.receive<Int>().unwrap { it.toString() }
} else {
otherSession.receive<String>().unwrap { it }
}
}
@Suspendable
@Override public Void call() throws FlowException {
int otherFlowVersion = otherSession.getCounterpartyFlowInfo().getFlowVersion();
String receivedString;
if (otherFlowVersion == 1) {
receivedString = otherSession.receive(Integer.class).unwrap(integer -> {
return integer.toString();
});
} else {
receivedString = otherSession.receive(String.class).unwrap(string -> {
return string;
});
}
return null;
}
This code shows a flow that in its first version expected to receive an Int, but in subsequent versions was modified to expect a String. This flow is still able to communicate with parties that are running the older CorDapp containing the older flow.
How do I deal with interface changes to inlined subflows?
Here is an example of an in-lined subflow:
@StartableByRPC
@InitiatingFlow
class FlowA(val recipient: Party) : FlowLogic<Unit>() {
@Suspendable
override fun call() {
subFlow(FlowB(recipient))
}
}
@InitiatedBy(FlowA::class)
class FlowC(val otherSession: FlowSession) : FlowLogic() {
// Omitted.
}
// Note: No annotations. This is used as an inlined subflow.
class FlowB(val recipient: Party) : FlowLogic<Unit>() {
@Suspendable
override fun call() {
val message = "I'm an inlined subflow, so I inherit the @InitiatingFlow's session ID and type."
initiateFlow(recipient).send(message)
}
}
@StartableByRPC
@InitiatingFlow
class FlowA extends FlowLogic<Void> {
private final Party recipient;
public FlowA(Party recipient) {
this.recipient = recipient;
}
@Suspendable
@Override public Void call() throws FlowException {
subFlow(new FlowB(recipient));
return null;
}
}
@InitiatedBy(FlowA.class)
class FlowC extends FlowLogic<Void> {
// Omitted.
}
// Note: No annotations. This is used as an inlined subflow.
class FlowB extends FlowLogic<Void> {
private final Party recipient;
public FlowB(Party recipient) {
this.recipient = recipient;
}
@Suspendable
@Override public Void call() {
String message = "I'm an inlined subflow, so I inherit the @InitiatingFlow's session ID and type.";
initiateFlow(recipient).send(message);
return null;
}
}
Inlined subflows are treated as being the flow that invoked them when initiating a new flow session with a counterparty.
Suppose flow A calls inlined subflow B, which, in turn, initiates a session with a counterparty. The FlowLogic
type used by the counterparty to determine which counter-flow to invoke is determined by A, and not by B. This
means that the response logic for the inlined flow must be implemented explicitly in the InitiatedBy flow. This can
be done either by calling a matching inlined counter-flow, or by implementing the other side explicitly in the
initiated parent flow. Inlined subflows also inherit the session IDs of their parent flow.
As such, an interface change to an inlined subflow must be considered a change to the parent flow interfaces.
An example of an inlined subflow is CollectSignaturesFlow. It has a response flow called SignTransactionFlow
that isn’t annotated with InitiatedBy. This is because both of these flows are inlined. How these flows speak to
one another is defined by the parent flows that call CollectSignaturesFlow and SignTransactionFlow.
In code, inlined subflows appear as regular FlowLogic instances without either an InitiatingFlow or an
InitiatedBy annotation.
Inlined flows are not versioned, as they inherit the version of their parent InitiatingFlow or InitiatedBy
flow.
Flows which are not an InitiatingFlow or InitiatedBy flow, or inlined subflows that are not called from an
InitiatingFlow or InitiatedBy flow, can be updated without consideration of backwards-compatibility. Flows of
this type include utility flows for querying the vault and flows for reaching out to external systems.
Flow drains
A flow checkpoint is a serialised snapshot of the flow’s stack frames and any objects reachable from the stack. Checkpoints are saved to the database automatically when a flow suspends or resumes, which typically happens when sending or receiving messages. A flow may be replayed from the last checkpoint if the node restarts. Automatic checkpointing is an unusual feature of Corda and significantly helps developers write reliable code that can survive node restarts and crashes. It also assists with scaling up, as flows that are waiting for a response can be flushed from memory.
However, this means that restoring an old checkpoint to a new version of a flow may cause resume failures. For example if you remove a local variable from a method that previously had one, then the flow engine won’t be able to figure out where to put the stored value of the variable.
For this reason, in currently released versions of Corda you must drain the node before doing an app upgrade that
changes @Suspendable code. A drain blocks new flows from starting but allows existing flows to finish. Thus once
a drain is complete there should be no outstanding checkpoints or running flows. Upgrading the app will then succeed.
A node can be drained or undrained via RPC using the setFlowsDrainingModeEnabled method, and via the shell using
the standard run command to invoke the RPC. See Node shell to learn more.
To assist in draining a node, the checkpoints dump shell command will output JSON representations of each checkpointed flow.
A zip containing the JSON files is created in the logs directory of the node. This information can then be used to determine the
state of stuck flows or flows that experienced internal errors and were kept in the node for manual intervention. To drain these flows,
the node will need to be restarted or the flow will need to be removed using killFlow.
killFlow can lead to an inconsistent ledger among transacting parties. Great care
and coordination with a flow’s counterparties must be taken to ensure that a initiating flow and flows responding to it are correctly
removed. This experience will be improved in the future. Making it easier to kill flows while notifying their counterparties.Contract and state versioning
There are two types of contract/state upgrade:
- Implicit: By allowing multiple implementations of the contract ahead of time, using constraints. See API: Contract Constraints to learn more.
- Explicit: By creating a special contract upgrade transaction and getting all participants of a state to sign it using the contract upgrade flows.
The general recommendation for Corda 4.10 is to use implicit upgrades for the reasons described here.
Performing explicit contract and state upgrades
In an explicit upgrade, contracts and states can be changed in arbitrary ways, if and only if all of the state’s participants agree to the proposed upgrade. To ensure the continuity of the chain the upgraded contract needs to declare the contract and constraint of the states it’s allowed to replace.
1. Preserve the existing state and contract definitions
Currently, all nodes must permanently keep all old state and contract definitions on their node’s classpath if the explicit upgrade process was used on them.
Contract Upgrade and Notary Change transactions will still be executed within the node classpath.2. Write the new state and contract definitions
Update the contract and state definitions. There are no restrictions on how states are updated. However,
upgraded contracts must implement the UpgradedContract interface. This interface is defined as:
interface UpgradedContract<in OldState : ContractState, out NewState : ContractState> : Contract {
val legacyContract: ContractClassName
fun upgrade(state: OldState): NewState
}
The upgrade method describes how the old state type is upgraded to the new state type.
By default this new contract will only be able to upgrade legacy states which are constrained by the zone whitelist (see API: Contract Constraints).
legacyContractConstraint arises from the fact that when a transaction chain is verified and a Contract Upgrade is
encountered on the back chain, the verifier wants to know that a legitimate state was transformed into the new contract. The legacyContractConstraint is
the mechanism by which this is enforced. Using it, the new contract is able to narrow down what constraint the states it is upgrading should have.
If a malicious party would create a fake com.megacorp.MegaToken state, he would not be able to use the usual MegaToken code as his
fake token will not validate because the constraints will not match. The com.megacorp.SuperMegaToken would know that it is a fake state and thus refuse to upgrade it.
It is safe to omit the legacyContractConstraint for the zone whitelist constraint, because the chain of trust is ensured by the Zone operator
who would have whitelisted both contracts and checked them.UpgradedContractWithLegacyConstraint
instead, and specify the constraint explicitly:interface UpgradedContractWithLegacyConstraint<in OldState : ContractState, out NewState : ContractState> : UpgradedContract<OldState, NewState> {
val legacyContractConstraint: AttachmentConstraint
}
For example, in case of hash constraints the hash of the legacy JAR file should be provided:
override val legacyContractConstraint: AttachmentConstraint
get() = HashAttachmentConstraint(SecureHash.parse("E02BD2B9B010BBCE49C0D7C35BECEF2C79BEB2EE80D902B54CC9231418A4FA0C"))
3. Create the new CorDapp JAR
Produce a new CorDapp JAR file. This JAR file should only contain the new contract and state definitions.
4. Distribute the new CorDapp JAR
Place the new CorDapp JAR file in the cordapps folder of all the relevant nodes. You can do this while the nodes are still
running.
5. Stop the nodes
Have each node operator stop their node. If you are also changing flow definitions, you should perform a node drain first to avoid the definition of states or contracts changing whilst a flow is in progress.
6. Re-run the network bootstrapper (only if you want to whitelist the new contract)
If you’re using the network bootstrapper instead of a network map server and have defined any new contracts, you need to re-run the network bootstrapper to whitelist the new contracts. See Network Bootstrapper.
7. Restart the nodes
Have each node operator restart their node.
8. Authorise the upgrade
Now that new states and contracts are on the classpath for all the relevant nodes, the next step is for all node to run the
ContractUpgradeFlow.Authorise flow. This flow takes a StateAndRef of the state to update as well as a reference
to the new contract, which must implement the UpgradedContract interface.
At any point, a node administrator may de-authorise a contract upgrade by running the
ContractUpgradeFlow.Deauthorise flow.
9. Perform the upgrade
Once all nodes have performed the authorisation process, a participant must be chosen to initiate the upgrade via the
ContractUpgradeFlow.Initiate flow for each state object. This flow has the following signature:
class Initiate<OldState : ContractState, out NewState : ContractState>(
originalState: StateAndRef<OldState>,
newContractClass: Class<out UpgradedContract<OldState, NewState>>
) : AbstractStateReplacementFlow.Instigator<OldState, NewState, Class<out UpgradedContract<OldState, NewState>>>(originalState, newContractClass)
This flow sub-classes AbstractStateReplacementFlow, which can be used to upgrade state objects that do not need a
contract upgrade.
Once the flow ends successfully, all the participants of the old state object should have the upgraded state object which references the new contract code.
10. Migrate the new upgraded state to the Signature Constraint from the zone constraint
Follow the guide in API: Contract Constraints.
Points to note
Capabilities of the contract upgrade flows
- Despite its name, the
ContractUpgradeFlowhandles the update of both state object definitions and contract logic - The state can completely change as part of an upgrade! For example, it is possible to transmute a
Catstate into aDogstate, provided that all participants in theCatstate agree to the change - If a node has not yet run the contract upgrade authorisation flow, they will not be able to upgrade the contract and/or state objects
- Upgrade authorisations can subsequently be deauthorised
- Upgrades do not have to happen immediately. For a period, the two parties can use the old states and contracts side-by-side
- State schema changes are handled separately
Writing new states and contracts
- If a property is removed from a state, any references to it must be removed from the contract code. Otherwise, you will not be able to compile your contract code. It is generally not advisable to remove properties from states. Mark them as deprecated instead
- When adding properties to a state, consider how the new properties will affect transaction validation involving this state. If the contract is not updated to add constraints over the new properties, they will be able to take on any value
- Updated state objects can use the old contract code as long as there is no requirement to update it
Permissioning
- Only node administrators are able to run the contract upgrade authorisation and deauthorisation flows
Logistics
- All nodes need to run the contract upgrade authorisation flow
- Only one node should run the contract upgrade initiation flow. If multiple nodes run it for the same
StateRef, a double-spend will occur for all but the first completed upgrade - The supplied upgrade flows upgrade one state object at a time
Serialization
Currently, the serialisation format for everything except flow checkpoints (which uses a Kryo-based format) is based upon AMQP 1.0, a self-describing and controllable serialisation format. AMQP is desirable because it allows us to have a schema describing what has been serialized alongside the data itself. This assists with versioning and deserialising long-ago archived data, among other things.
Writing classes
Although not strictly related to versioning, AMQP serialisation dictates that we must write our classes in a particular way:
- Your class must have a constructor that takes all the properties that you wish to record in the serialized form. This is required in order for the serialization framework to reconstruct an instance of your class
- If more than one constructor is provided, the serialization framework needs to know which one to use. The
@ConstructorForDeserializationannotation can be used to indicate the chosen constructor. For a Kotlin class without the@ConstructorForDeserializationannotation, the primary constructor is selected - The class must be compiled with parameter names in the .class file. This is the default in Kotlin but must be turned
on in Java (using the
-parameterscommand line option tojavac) - Your class must provide a Java Bean getter for each of the properties in the constructor, with a matching name. For
example, if a class has the constructor parameter
foo, there must be a getter calledgetFoo(). Iffoois a boolean, the getter may optionally be calledisFoo(). This is why the class must be compiled with parameter names turned on - The class must be annotated with
@CordaSerializable - The declared types of constructor arguments/getters must be supported, and where generics are used the generic parameter must be a supported type, an open wildcard (*), or a bounded wildcard which is currently widened to an open wildcard
- Any superclass must adhere to the same rules, but can be abstract
- Object graph cycles are not supported, so an object cannot refer to itself, directly or indirectly
Writing enums
Elements cannot be added to enums in a new version of the code. Hence, enums are only a good fit for genuinely static
data that will never change (e.g. days of the week). A Buy or Sell flag is another. However, something like
Trade Type or Currency Code will likely change. For those, it is preferable to choose another representation,
such as a string.
State schemas
By default, all state objects are serialised to the database as a string of bytes and referenced by their StateRef.
However, it is also possible to define custom schemas for serialising particular properties or combinations of
properties, so that they can be queried from a source other than the Corda Vault. This is done by implementing the
QueryableState interface and creating a custom object relational mapper for the state. See API: Persistence
for details.
For backwards compatible changes such as adding columns, the procedure for upgrading a state schema is to extend the existing object relational mapper. For example, we can update:
object ObligationSchemaV1 : MappedSchema(Obligation::class.java, 1, listOf(ObligationEntity::class.java)) {
@Entity @Table(name = "obligations")
class ObligationEntity(obligation: Obligation) : PersistentState() {
@Column var currency: String = obligation.amount.token.toString()
@Column var amount: Long = obligation.amount.quantity
@Column @Lob var lender: ByteArray = obligation.lender.owningKey.encoded
@Column @Lob var borrower: ByteArray = obligation.borrower.owningKey.encoded
@Column var linear_id: String = obligation.linearId.id.toString()
}
}
public class ObligationSchemaV1 extends MappedSchema {
public ObligationSchemaV1() {
super(Obligation.class, 1, ImmutableList.of(ObligationEntity.class));
}
}
@Entity
@Table(name = "obligations")
public class ObligationEntity extends PersistentState {
@Column(name = "currency") private String currency;
@Column(name = "amount") private Long amount;
@Column(name = "lender") @Lob private byte[] lender;
@Column(name = "borrower") @Lob private byte[] borrower;
@Column(name = "linear_id") private UUID linearId;
protected ObligationEntity(){}
public ObligationEntity(String currency, Long amount, byte[] lender, byte[] borrower, UUID linearId) {
this.currency = currency;
this.amount = amount;
this.lender = lender;
this.borrower = borrower;
this.linearId = linearId;
}
public String getCurrency() {
return currency;
}
public Long getAmount() {
return amount;
}
public byte[] getLender() {
return lender;
}
public byte[] getBorrower() {
return borrower;
}
public UUID getLinearId() {
return linearId;
}
}
To:
object ObligationSchemaV1 : MappedSchema(Obligation::class.java, 1, listOf(ObligationEntity::class.java)) {
@Entity @Table(name = "obligations")
class ObligationEntity(obligation: Obligation) : PersistentState() {
@Column var currency: String = obligation.amount.token.toString()
@Column var amount: Long = obligation.amount.quantity
@Column @Lob var lender: ByteArray = obligation.lender.owningKey.encoded
@Column @Lob var borrower: ByteArray = obligation.borrower.owningKey.encoded
@Column var linear_id: String = obligation.linearId.id.toString()
@Column var defaulted: Bool = obligation.amount.inDefault // NEW COLUMN!
}
}
public class ObligationSchemaV1 extends MappedSchema {
public ObligationSchemaV1() {
super(Obligation.class, 1, ImmutableList.of(ObligationEntity.class));
}
}
@Entity
@Table(name = "obligations")
public class ObligationEntity extends PersistentState {
@Column(name = "currency") private String currency;
@Column(name = "amount") private Long amount;
@Column(name = "lender") @Lob private byte[] lender;
@Column(name = "borrower") @Lob private byte[] borrower;
@Column(name = "linear_id") private UUID linearId;
@Column(name = "defaulted") private Boolean defaulted; // NEW COLUMN!
protected ObligationEntity(){}
public ObligationEntity(String currency, Long amount, byte[] lender, byte[] borrower, UUID linearId, Boolean defaulted) {
this.currency = currency;
this.amount = amount;
this.lender = lender;
this.borrower = borrower;
this.linearId = linearId;
this.defaulted = defaulted;
}
public String getCurrency() {
return currency;
}
public Long getAmount() {
return amount;
}
public byte[] getLender() {
return lender;
}
public byte[] getBorrower() {
return borrower;
}
public UUID getLinearId() {
return linearId;
}
public Boolean isDefaulted() {
return defaulted;
}
}
Thus adding a new column with a default value.
To make a non-backwards compatible change, the ContractUpgradeFlow or AbstractStateReplacementFlow must be
used, as changes to the state are required. To make a backwards-incompatible change such as deleting a column (e.g.
because a property was removed from a state object), the procedure is to define another object relational mapper, then
add it to the supportedSchemas property of your QueryableState, like so:
override fun supportedSchemas(): Iterable<MappedSchema> = listOf(ExampleSchemaV1, ExampleSchemaV2)
@Override public Iterable<MappedSchema> supportedSchemas() {
return ImmutableList.of(new ExampleSchemaV1(), new ExampleSchemaV2());
}
Then, in generateMappedObject, add support for the new schema:
override fun generateMappedObject(schema: MappedSchema): PersistentState {
return when (schema) {
is DummyLinearStateSchemaV1 -> // Omitted.
is DummyLinearStateSchemaV2 -> // Omitted.
else -> throw IllegalArgumentException("Unrecognised schema $schema")
}
}
@Override public PersistentState generateMappedObject(MappedSchema schema) {
if (schema instanceof DummyLinearStateSchemaV1) {
// Omitted.
} else if (schema instanceof DummyLinearStateSchemaV2) {
// Omitted.
} else {
throw new IllegalArgumentException("Unrecognised schema $schema");
}
}
With this approach, whenever the state object is stored in the vault, a representation of it will be stored in two separate database tables where possible - one for each supported schema.
Testing CorDapp upgrades
At the time of this writing there is no platform support to test CorDapp upgrades. There are plans to add support in a future version. This means that it is not possible to write automated tests using just the provided tooling.
To test an implicit upgrade, you must simulate a network that initially has only nodes with the old version of the CorDapp, and then nodes gradually transition to the new version. Typically, in such a complex upgrade scenario, there must be a deadline by which time all nodes that want to continue to use the CorDapp must upgrade. To achieve this, this deadline must be configured in the flow logic which must only use new features afterwards.
This can be simulated with a scenario like this:
- Write and individually test the new version of the state and contract.
- Setup a network of nodes with the previous version. In the simplest form, deployNodes can be used for this purpose.
- Run some transactions between nodes.
- Upgrade a couple of nodes to the new version of the CorDapp.
- Continue running transactions between various combinations of versions. Also make sure transactions that were created between nodes with the new version are being successfully read by nodes with the old CorDapp.
- Upgrade all nodes and simulate the deadline expiration.
- Make sure old transactions can be consumed, and new features are successfully used in new transactions.
Was this page helpful?
Thanks for your feedback!
Chat with us
Chat with us on our #docs channel on slack. You can also join a lot of other slack channels there and have access to 1-on-1 communication with members of the R3 team and the online community.
Propose documentation improvements directly
Help us to improve the docs by contributing directly. It's simple - just fork this repository and raise a PR of your own - R3's Technical Writers will review it and apply the relevant suggestions.
We're sorry this page wasn't helpful. Let us know how we can make it better!
Chat with us
Chat with us on our #docs channel on slack. You can also join a lot of other slack channels there and have access to 1-on-1 communication with members of the R3 team and the online community.
Create an issue
Create a new GitHub issue in this repository - submit technical feedback, draw attention to a potential documentation bug, or share ideas for improvement and general feedback.
Propose documentation improvements directly
Help us to improve the docs by contributing directly. It's simple - just fork this repository and raise a PR of your own - R3's Technical Writers will review it and apply the relevant suggestions.